library(shiny)
ask_chatgpt <- function(prompt) {
# code to make the request
}
ui <- fluidPage(
textInput("prompt", "Enter your prompt"),
actionButton("send", "Send prompt"),
uiOutput("response")
)
server <- function(input, output, session) {
output$reponse <- renderUI({
ask_chatgpt(input$prompt) |>
shiny::markdown()
}) |>
bindEvent(input$send)
}
shinyApp(ui, server)On updating a chat assistant app for the RStudio IDE
rweekly
This post summarizes the challenges overcomed while trying to improve three areas of the ChatGPT addin (shiny app) from {gptstudio}.
The whole journey began quite unexpectedly for me. I was developing a shiny app for my work and decided to venture into writing JavaScript code. However, I felt that the autocomplete feature in the RStudio IDE wasn’t the best available. So, I decided to give VSCode a shot.
As I’m not well versed with JS (or VSCode), I was requesting a lot of help from ChatGPT. That’s when I stumbled upon the Genie extension, which integrates ChatGPT seamlessly into the IDE (provided you have a valid API key). That got me thinking: shouldn’t we have a similar integration for the RStudio IDE?
It turns out, I wasn’t the only one who had this idea. Version 0.1.0 of {gptstudio} was already on CRAN, so I decided to give its ChatGPT addin a try. To my surprise, it exceeded my expectations, and I was intrigued to explore it further. I enthusiastically checked out its GitHub repository and couldn’t resist giving it a well-deserved star. As I dug deeper, I made an unexpected discovery—an open issue with a help wanted label.
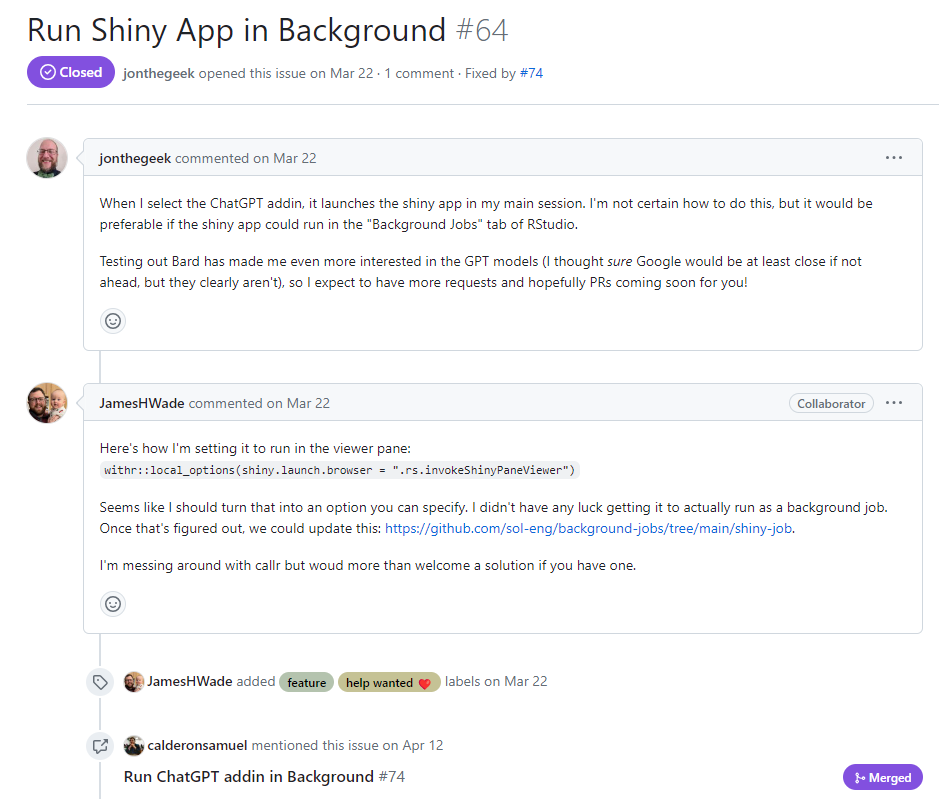
Run Shiny App in Background - issue #64
Isn’t that the guy from the R4DS slack channel? Also, I agree with him
This was the perfect issue to try to solve. Just a few days prior, I had watched a video discussing RStudio jobs for shiny apps. Although I couldn’t locate the video at the time of writing this, I did find a README file containing the relevant information.
To sum it up, I discovered that it is possible to launch an app as a background job and then open it from the R console. This functionality extends to shiny apps that are addins from a package. By doing this, you can have your background shiny app displayed in the Viewer pane of the RStudio IDE.
After trying this in my fork of the package, I documented all my code and submitted a Pull Request to the maintainers, which was integrated in very short time. I was very happy with this but still thought that there some things that could be improved.
The UI should resemble a chat
Even though at the moment you were able to have your chat assistant, the UI was a bit awkward to navigate when you had a long chat history. I had the intention to just move the text input to the bottom of the app, like in a chat window. In order to do that, I thought that I should incorporate shiny modules and separate the app into smaller, more manageable components. Okay, this was a couple more lines of code than I expected. After that, I thought that the viewer pane was very small to have a lot of controls always visible and decided to hide some inputs in a “Configuration” dropdown button.
But shiny doesn’t have native dropdown buttons. Should I import bs4Dash just to have them? Should I make my own? Maybe the theme colors are a bit weird. Should I change them? How on earth will I test all these changes? Will the previous tests even pass? I would love to have the app’s theme match the RStudio IDE theme of every user. I would also love to provide a welcome message to the users. Oh man, I would totally love to have a “Copy” button on every code chunk provided in the responses (this was the hardest thing to get done).
In the end, the small contribution I intended to make was 59 commits long, and I won’t even say how many files were affected. I was very hesitant to make a pull request for something nobody had asked for, so I went for the “Discussions” tab.
Me: Hey guys, I did this. I haven’t done a PR yet because no one really asked for this…
JamesHWade: This is fantastic! I would very much welcome a PR. Great work!!!
MichelNivard: Amazing! Yes, please submit a PR. I would love this!
Okay then. Pull request merged!! So, what was the difficult part? Here comes the code.
The copy button
As I said before, I really wanted to have a button to easily add any code chunk text to the user’s system clipboard. At the time, I was unsure about doing it in R or in JS. I’ll explain why.
When you send a prompt to ChatGPT, it will, by default, respond in markdown. You can easily convert that to HTML with shiny::markdown() and render it dynamically. A minimal shiny app to do that would look like this:
A flowchart representing this app would look like this:

This receives a response, converts it to HTML, and sends it to the browser to be displayed. Every code chunk present would be wrapped inside a <pre> HTML tag, and because we aim to prepend a copy button to them, this tag should be the selector for any future manipulation.
Now, we need to decide whether to do it in R or in JS. My first instinct was to do it via JS once the full answer was rendered. I would need a listener for a render event on any <pre> tag. This was my first attempt:
$('pre').each(function() {
const $codeChunk = $(this);
const $copyButton = $('<button>').text('Copy');
$codeChunk.prepend($copyButton);
$copyButton.on('click', function() {
const codeText = $codeChunk.text();
navigator.clipboard.writeText(codeText);
});
});This can prepend a “Copy” button to a code chunk, but it doesn’t do it automatically after rendering. In fact, there is nothing in that code to handle the render event. I searched a lot for methods to achieve that, but unfortunately, I wasn’t able to find or understand the necessary code to implement it (remember that all this began because I wasn’t well-versed in JS). So, in the end, I would have to do it from R.
So, what is the best way to manipulate HTML tags in R? From my point of view, it is by using htmltools::tagQuery() and its corresponding methods. However, that function requires a tag(), tagList(), or a list() of tags. I didn’t have that. Compare these outputs:
htmltools::h1("Title 1") |> class()#> [1] "shiny.tag"shiny::markdown("# Title 1") |> class()#> [1] "html" "character"Well then, can’t we just add the “shiny.tag” class to the rendered markdown to be able to use tagQuery()? Well…
tag_example <- shiny::markdown("# Title 1")
class(tag_example) <- c(class(tag_example), "shiny.tag")
htmltools::tagQuery(tag_example)#> Error in list2env(xList, new.env(parent = emptyenv())): first argument must be a named listI invite you to try to understand that error message. I, however, decided not to try. What should we do now? Is there a way to convert an "html" character to an object that tagQuery() can handle? Not that I knew of. But, after a not-so-quick Google search, I came across this Github repo where Alan Dipert had shared a shiny app to handle that conversion. His code covered almost every tag conversion, but it didn’t work for all my tests and used the {XML} package, which was totally unfamiliar to me.
I decided to implement a new version of the code with {xml2}, {glue}, and {purrr} at its core, which I managed to get working after several tries. You can see the code in this snapshot.
Code
library(magrittr)
#' Convert HTML to a Tag List
#'
#' This function takes a character string of HTML code and returns a tag list that can be used to
#' display the HTML content in an R Markdown document or Shiny app. The resulting tag list can be
#' passed as an argument to the `htmltools::tagQuery()` function or used as an input to other HTML
#' rendering functions in R.
#'
#' @param html A character string of HTML code
#' @return A tag list that can be used to display the HTML content
#' @export
html_to_taglist <- function(html) {
html %>%
html_to_r() %>%
parse(text = .) %>%
eval()
}
#' Convert HTML to R Code
#'
#' This function takes a character string of HTML code and returns a styled R code that can be used
#' to recreate the HTML structure. The resulting R code is a character string that can be copied and
#' pasted into an R script or console.
#'
#' @param html A character string of HTML code
#' @return A character string of styled R code that can be used to recreate the HTML structure
#' @export
html_to_r <- function(html) {
html %>%
html_str_to_nodeset() %>%
purrr::map(get_node_params) %>%
purrr::map_chr(node_params_to_str) %>%
glue::glue_collapse(sep = ", ") %>%
into_taglist()
}
#' HTML string to xml nodeset
#'
#' This function takes HTML defined as a string and returns it as a xml_nodeset.
#'
#' @param str A character string that represents the HTML to be parsed
#' @return A nodeset representing the parsed HTML
html_str_to_nodeset <- function(str) {
str %>%
xml2::read_html() %>%
xml2::xml_find_all("./body/*")
}
node_is_text <- function(node) xml2::xml_name(node) == "text"
node_text_is_empty <- function(node) xml2::xml_text(node, trim = TRUE) == ""
node_content_is_nodeset <- function(node) "xml_nodeset" %in% class(node$contents)
node_content_is_empty <- function(node) length(node$content) == 0
#' Get Nodeset Tag Contents
#'
#' This function takes a nodeset and returns the contents of each tag.
#'
#' @param nodeset A nodeset representing a parsed HTML document
#' @return A character vector containing the contents of each tag in the nodeset
get_nodeset_tag_contents <- function(nodeset) {
nodeset %>%
xml2::xml_contents() %>%
purrr::discard(\(node) node_is_text(node) && node_text_is_empty(node))
}
#' Get Node Parameters
#'
#' This function takes a node and returns a list with its name, attributes, and contents.
#' This functions applies recursively to every element of its contents until the element is plain text or has no extra content.
#'
#' @param node A node representing an element or text node in a parsed HTML document
#' @return A list with the name, attributes, and contents of the node
#'
get_node_params <- function(node) {
if (node_is_text(node)) {
list(
name = "text",
attrs = xml2::xml_attrs(node),
contents = xml2::xml_text(node)
)
} else {
node_with_params <- list(
name = xml2::xml_name(node),
attrs = xml2::xml_attrs(node),
contents = get_nodeset_tag_contents(node)
)
if (node_content_is_nodeset(node_with_params) && !node_content_is_empty(node_with_params)) {
node_with_params$contents <- node_with_params$contents %>%
purrr::map(get_node_params)
}
node_with_params
}
}
#' Convert Attributes to Parameters
#'
#' This function takes a named character vector representing attributes and returns a character string
#' that can be used as a parameter list in an HTML tag.
#'
#' @param attrs A named character vector representing attributes
#' @return A character string that can be used as a parameter list in an HTML tag
attrs_to_params <- function(attrs) {
if (length(attrs) == 0) return("")
params_names <- names(attrs)
params_values <- unname(attrs)
params <- glue::glue("`{params_names}` = \"{params_values}\"")
glue::glue_collapse(params, ", ")
}
#' Convert Node Parameters to String
#'
#' This function takes a list of parameters for an HTML tag and returns a character string that
#' represents the tag with the given parameters. Aplies recursively to every child content until
#' content is text or empty.
#'
#' @param node_params A list of parameters for an HTML tag
#' @return A character string that represents the tag with the given parameters
#'
node_params_to_str <- function(node_params) {
if (node_params$name == "text") {
safe_text <- gsub("'", "\\\\'", node_params$contents)
glue::glue("'{safe_text}'")
} else {
tag_name <- glue::glue("htmltools::tags${node_params$name}")
params <- attrs_to_params(node_params$attrs)
contents <- node_params$contents
if (length(contents) > 0) {
contents <- contents %>%
purrr::map_chr(node_params_to_str) %>%
glue::glue_collapse(sep = ", ")
# contents <- paste0(", ", contents)
} else {
contents <- ""
}
fun_args <- c(params, contents)
fun_args <- fun_args[fun_args != ""]
fun_args <- paste(fun_args, collapse = ", ")
glue::glue("{tag_name}({fun_args})")
}
}
#' Paste tags string inside a tagList
#'
#' This function takes a list of HTML tags and returns a character string that, when evaluated,
#' will produce a tagList object containing the given tags.
#'
#' @param tags_str A list of HTML tags
#' @return A character string that, when evaluated, will produce a tagList object containing the given tags
into_taglist <- function(tags_str) {
glue::glue("htmltools::tagList({tags_str})")
}After that, I was able to run the following:
md_example <- "# Title\n\nSome paragraph content.\n\n```\n# some code content\n```"
md_rendered <-shiny::markdown(md_example)
md_translated <- html_to_taglist(md_rendered)
tq_example <- htmltools::tagQuery(md_translated)
tq_example#> `$allTags()`:
#> <h1>Title</h1>
#> <p>Some paragraph content.</p>
#> <pre>
#> <code># some code content
#> </code>
#> </pre>
#>
#> `$selectedTags()`: `$allTags()`This meant that I was able to use tagQuery()! With this, prepending a copy button is not so difficult. You just need a combination of htmltools::tags$button() and tq$children('pre')$before(). Of course, you also need to handle the copy action in JS, which was already done in the first attempt. So, all of this was integrated into the development version of {gptstudio}.
At this point, the flowchart of the app would look like this:

Now, let’s take a look at what happens when we compare the character contents of md_rendered and md_translated.
as.character(md_rendered)#> [1] "<h1>Title</h1>\n<p>Some paragraph content.</p>\n<pre><code># some code content\n</code></pre>\n"as.character(md_translated)#> [1] "<h1>Title</h1>\n<p>Some paragraph content.</p>\n<pre>\n <code># some code content\n</code>\n</pre>"My translation inserts unnecessary white space between the opening of the <pre> and the <code> tags. This results in a weird “indentation” on the first line of every code chunk. This didn’t break the app’s behavior but it was ugly, and I wasn’t really sure why this was happening or how to fix it.
Fortunately, Iakov Davydov took notice of it and, in addition to fixing the translation, actually implemented the copy button mechanism in JS, super-seeding my translation efforts. This person also wrote the original attempt at using the “Enter” key as an alternative to clicking the “Send” button.
With this, the app could be represented with the following flowchart:

Of course, this is a lot simpler. All of this was added in the development version of the package, and my translation code had to be removed. This was bittersweet because it wasn’t too easy to achieve, but I understood that it was for the better.
Receiving a response shouldn’t take too long
At this point we had a better looking app with friendlier input controls. But rendering a response was s-l-o-w. The app had to wait for the whole answer before rendering it. If you look carefully at Figure 3 you’ll see that it represents a sequential flow. We need to wait for ask_chatgpt() to complete before doing anything with the response. But this is not the experience people have while using the original ChatGPT.
In the web, you can see the response being generated in real time almost word by word with a typewriter-like effect. In fact, my first assumption was that the ChatGPT web app received its full response much faster than I did with my API requests because of my slow (Peruvian) connection, and that once it had the full response, it rendered it with a typewriter-like animation to ease the user’s reading process.
Well, I was totally wrong. It turns out that the API offers the option to stream the response. This means that you can get the response while it is being generated, chunk by chunk. So, the typewriter-like effect doesn’t actually exist, the response is being constantly rendered while the chunks arrive.
So, to get the same thing in {gptstudio} we should just activate the stream option right? Well, yes, but the flow described in Figure 3 can’t render the response while it is being streamed. This requires a two step solution that I’ll describe now.
Warning
Before you continue reading this section, I want to say that what comes can be hard to understand. I’m focusing on providing clear explanations rather than precise ones. There are some additional processes going on in the chat app that I don’t talk about to avoid distractions.
In addition, I’m a Peruvian political scientist turned self-taught data analyst, not a computer scientist or a software engineer. So, be patient with me if I happen to have gaps in my programming knowledge, or if I don’t use technical terms with precision, or even if I don’t use English correctly. Having that clear, let’s continue.
Read the stream in R
At this point in time, I’m not aware of any R project that uses streaming for the OpenAI API. Making traditional http requests is rather straight forward with {httr2}. In fact, the internals of {gptstudio} where all based on {httr} functions that were later translated to {httr2}. So, how can we use streaming for this project?
The API documentation provides a guide on how to stream completions. EZ, you just need to use the openai python library! I imagine there are ways to wrap that library and access it from an app to be used as an addin in RStudio, but I also imagine it would make the setup much more harder than it needs to be.
The OpenAI team also supports an official Node.js library, but it’s README file states that it doesn’t natively support streaming. So, no easy way to stream chat completions from JS either. It is worth mentioning that setting up a Node.js package to be used in the app would’ve still been very hard for me (remember that all these began with me being bad at writing JS code?). So R it is.
As I mentioned before, we were using {httr2} for every API interaction. This package provides a req_stream() function that aims to facilitate streaming and sounded really promising. But a problem arised quickly: the format of the streaming response was hard to process.
To illustrate the problem, let’s consider prompting “Count from 1 to 5” and receiving a chat completion response without streaming. After after assigning it to the resp_example object, it would look like this:
resp_example#> {
#> "metadata": "some-metadata",
#> "choices": [
#> {
#> "message": {
#> "role": "assistant",
#> "content": "1, 2, 3, 4, 5"
#> }
#> }
#> ],
#> "other-metadata": "more-metadata"
#> }The real content of the response is located inside resp_example$choices[[1]]$message$content (markdown). The length of this string is directly proportional to the time it takes to receive the response. This operation is located in the ask_chatgpt() process in Figure 3.
When we use httr2::req_stream() we receive the full response in chunks while they stream. If we provide the print function as a callback (to be applied at every chunk while it arrives) it would look like the following:
#> [1] "{\n \"me"
#> [1] "tadata\""
#> [1] ": \"some"
#> [1] "-metada"
#> [1] "ta\",\n "
#> [1] "\"choice"
#> [1] "s\": [\n "
#> [1] " {\n "
#> [1] " \"me"
#> [1] "ssage\":"
#> [1] " {\n "
#> [1] " \"ro"
#> [1] "le\": \"a"
#> [1] "ssistan"
#> [1] "t\",\n "
#> [1] " \"c"
#> [1] "ontent\""
#> [1] ": \"1, 2"
#> [1] ", 3, 4,"
#> [1] " 5\"\n "
#> [1] " }\n "
#> [1] " }\n ]"
#> [1] ",\n \"ot"
#> [1] "her-met"
#> [1] "adata\":"
#> [1] " \"more-"
#> [1] "metadat"
#> [1] ""I assumed that was good enough. You can process the chunks as they arrive and apply some clever logic to pull out just the content of the response. This send me down a rabbit hole to get to that clever logic, and it turns out that processing an incomplete JSON with regular expressions is as fun as it sounds. Never forget this legendary quote:
Some people, when confronted with a problem, think “I know, I’ll use regular expressions.” Now they have two problems.
Jamie Zawinski
Looking for an alternative, I checked the OpenAI guide again, and I realized that the python library returns not the full response in chunks, but just the content in chunks that individually can be treated as JSON text. How do they do it?
Another rabbit hole looking at the guts of the openai python library. Nothing there suggests that they are doing anything extraordinary to read the stream in chunks of the content. But a nice thing in a python script (even if it is located inside a library) is that you can always see directly the packages it imports. There I found the requests library being imported, which pointed me to the very low level urllib3 library.
What if we do the same exploration for R? {gptstudio} depends on {httr2}, which in turn depends on {curl}, which has libcurl as system requirement. Can libcurl do for {gptstudio} the same that urllib3 does for the openai python library? The answer is YES!!! I tried the curl example from the OpenAI docs with stream activated directly in the terminal.
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Count from 1 to 5"}],
"stream": "true"
}'And boom! It worked in the first try! And it gets better. It turns out that {curl} already provides the curl_fetch_stream() function to avoid messing directly with libcurl in the terminal. In fact, httr2::req_stream() makes use of that function, with the caveat that for some reason it streams the full response instead of the content, as I explained before.
Now, if we just pass the print method as a callback for curl_fetch_stream(), the streaming chunks look like this:
#> {
#> "choices": [
#> {
#> "delta": {
#> "content": "1, "
#> }
#> }
#> ],
#> "metadata": "some-metadata",
#> "other-metadata": "more-metadata"
#> }
#> {
#> "choices": [
#> {
#> "delta": {
#> "content": "2,"
#> }
#> }
#> ],
#> "metadata": "some-metadata",
#> "other-metadata": "more-metadata"
#> }
#> {
#> "choices": [
#> {
#> "delta": {
#> "content": " 3, "
#> }
#> }
#> ],
#> "metadata": "some-metadata",
#> "other-metadata": "more-metadata"
#> }
#> {
#> "choices": [
#> {
#> "delta": {
#> "content": "4, "
#> }
#> }
#> ],
#> "metadata": "some-metadata",
#> "other-metadata": "more-metadata"
#> }
#> {
#> "choices": [
#> {
#> "delta": {
#> "content": "5"
#> }
#> }
#> ],
#> "metadata": "some-metadata",
#> "other-metadata": "more-metadata"
#> }As you can see, every chunk is the same, except for the content field. From this, is just a matter of reading each chunk as JSON and doing whatever we want with the content from the callback passed to curl_fetch_stream(). We can wrap that functionality in a stream_chatgpt() function to slightly modify the current flow of the app.

Even though we are able to read the content chunk by chunk, we are still waiting for the whole content to arrive before rendering something to the browser. That’s that we need to tackle next.
Render the stream without reactivity
Now that we can receive the response as a stream, we need to talk about reactivity. There is no better explanation about this topic that the one Hadley Wickham provides in Mastering Shiny. The chapter about the reactive graph made me feel like I was unlocking a superpower, and I encourage everyone to give it a try.
In short, it explains how your inputs, reactive expressions and outputs are part of a big and clever reactive process (represented in the reactive graph) that dinamycally updates the data used in your app whenever a change is observed. However, we must have in mind that this process executes sequentially, meaning that R needs to complete one task before starting to work in a new one, as it happens in the flow represented by Figure 4.
So we need to render the chunks as they arrive while the reactive process is blocked by the unfinished stream. Having the R process blocked means that we can’t rely on reactives or observers to handle changes in the data present in our app or render the content of the streaming chunks.
Luckily, the session object present in every server of a shiny app provides the sendCustomMessage() method to communicate with the browser. This means that we need to use that method inside of the callback provided to curl_fetch_stream() running inside stream_chatgpt(), and send to the browser the accumulated content that keeps arriving as individual chunks.
I hope you can understand that tongue-twister better with the following figure:

As you can see, we do the same thing that we did before, it just happens that now we do it chunk by chunk as they arrive. The copy button is still handled at the very end because there is really no need to do it chunk by chunk.
And with this, you have a better looking chat app, with a copy button, that renders responses in real time.
Final thoughts
All of this began with an open issue in the package’s GitHub repository. If you are developing a project that you think could use some help from the public, going open source and announcing that you need help will drastically improve the chances of, well, getting help. Not only that, an open-source project has better chances of receiving feedback such as bug reports or feature requests.
On the other hand, don’t be afraid of forking an open-source project and trying to make changes to it. At the very least, you can put into practice the knowledge you already have by attempting to fix some of its issues, and in the best-case scenario, you will also learn a lot of new things while challenging yourself to extend the project’s features. While not everything you try will necessarily end up being used for the project, the practice and learning will remain with you for your future projects.
Feel free to give it a try with:
install.packages("gptstudio")Any feedback on the Github repo will be greatly appreciated.